生成AIの自動評価について
従来、生成AIの評価は人が直接見て評価するという方法が中心でしたが、それは大きな労力を必要とする作業となっていました。自動評価を活用することで、人に依存しない一貫性のある評価を即時に行うことができます。
しかし、評価指標としてよく耳にする、文章の流暢さや意味の一貫性、事実性、創造性、BLEUやROUGE、LLM-as-a-Judgeといったものを自力で実装していくには、これまた相当な労力が必要となり、全てを投げ出したい気持ちになります。
そんな時に、私は自動評価ライブラリというものを見つけました。
自動評価ライブラリは調べるといくつか見つけることができましたが、その中でも「これはかなり使えるんじゃないか!」と思った“promptfoo”というライブラリについて深ぼって動作確認を行なってみたので、その内容をご紹介します。
promptfooとは
LLMの評価を自動で行うことのできるオープンソースのCLI およびライブラリです。(MIT License)
評価方法は様々なものがあるので、任意のものを設定して評価を行うことができます。高度な評価方法であるLLM-as-a-Judgeも簡単に実行することができ、pyhon上で実装したLLMの出力を読み込ませて評価するということも可能です。
私の個人的に一番良いと思ったのが、評価結果がブラウザ上でグラフィカルに確認できるという点です。
LLMの自動評価にはOpenAI Evalなどもありますが、結果の出し方が圧倒的にpromptfooの方が綺麗なものが出せるなと思いました。
promptfooのインストール
promptfooはnpmコマンドを使ってインストールを行います。
※npmがインストールされていない場合は、先にNode.jsをインストールしてください。
npm install -g promptfoo「-g」 は、グローバル(PC全体で使用できる)にインストールを行うという意味になります。
現在のフォルダ内で完結させたい場合は、「-g」を抜いて実行してください。
また、インストールフォルダに権限がなく、インストールに失敗する場合がありますが、その場合「sudo」をつけて実行してください。
以下のコマンドでpromptfooのインストールが正常に行われたかを確認できます。
promptfoo --version作業を行いたいフォルダ上で、以下のコマンドを実行してpromptfooの.yamlを作成します。
※このコマンドを実行しないとpromptfooが使えないわけではありませんが、実行に必要な.yamlファイルのサンプルが出力されるので、初めての場合はこちらでできたサンプルをもとにお試ししていくと理解しやすいかと思います。
promptfoo initそうすると、実行したフォルダの直下に以下のファイルが出力されます。
・promptfooconfig.yaml ←こっちを使います
・README.md
promptfooconfig.yaml についての説明
「promptfooconfig.yaml」はpromptfooを実行するために必要な設定ファイルになります。
こちらに記載されている内容によって評価が実行されます。
簡単な例を見てみましょう。
以下は、”AIについて100文字以内で説明してください。”という質問をLLMに回答してもらい、①回答に”AI”という文字が含まれている、②回答に”こんにちは”という文字が含まれているか。といった2つの評価を行うものになります。
description: "My eval"
prompts:
- "AIについて100文字以内で説明してください。"
providers:
- id: azureopenai:chat:xxxxxx #deploymentName
config:
apiHost: 'https://xxxxxxxx.openai.azure.com'
tests:
- vars:
topic: 「AI」という文字が含まれるかどうか
assert:
- type: icontains
value: AI
- vars:
topic: 「こんにちは」という文字が含まれるかどうか
assert:
- type: icontains
value: こんにちは■各項目の説明
- description:
テストの名前を記載します。結果をWebで確認できるのですが、その際に名称がつきます。 - prompts:
評価時にLLMに渡したいプロンプト。複数行を記載して一度に複数のプロンプトの評価を行うこともできます。 - providers:
評価時に使用したいLLMを指定します。
例では、Azure OpenAI Service を設定しており、デプロイ名とエンドポイントを記載します。 - tests:
評価したい内容を記載します。
-vars:
変数を設定する項目になりますが、このvarsの数だけ一度にテストが実行されます。
-topic:
テスト名を記載します。
-assert:
この項目の「type」にテストの種類を設定します。
例の”icontains”は、“value”に設定した値が回答に含まれているかを確認するテストとなります。
promptfooではほとんどの場合、実行時にLLMを使うようになりますので、LLMを実行するためのAPIキーも合わせて設定する必要があります。
「providers」に直接記載することは可能ですが、セキュリティ的に良くないので、環境変数に入れてあげましょう。
Azure OpenAI Serviceを使う場合は、以下のように設定します。
・AZURE_API_KEY:XXXXXXXXX ※使用するKEYを設定する
promptfooの実行方法
promptfooを実行するには、「promptfooconfig.yaml」があるフォルダ上で、下記コマンドを実行します。
promptfoo evalするとコマンドライン上で結果が表示されます。
結果はコマンドライン上だけでなく、以下のコマンドを実行することでブラウザでも確認することができます。
promptfoo view --yes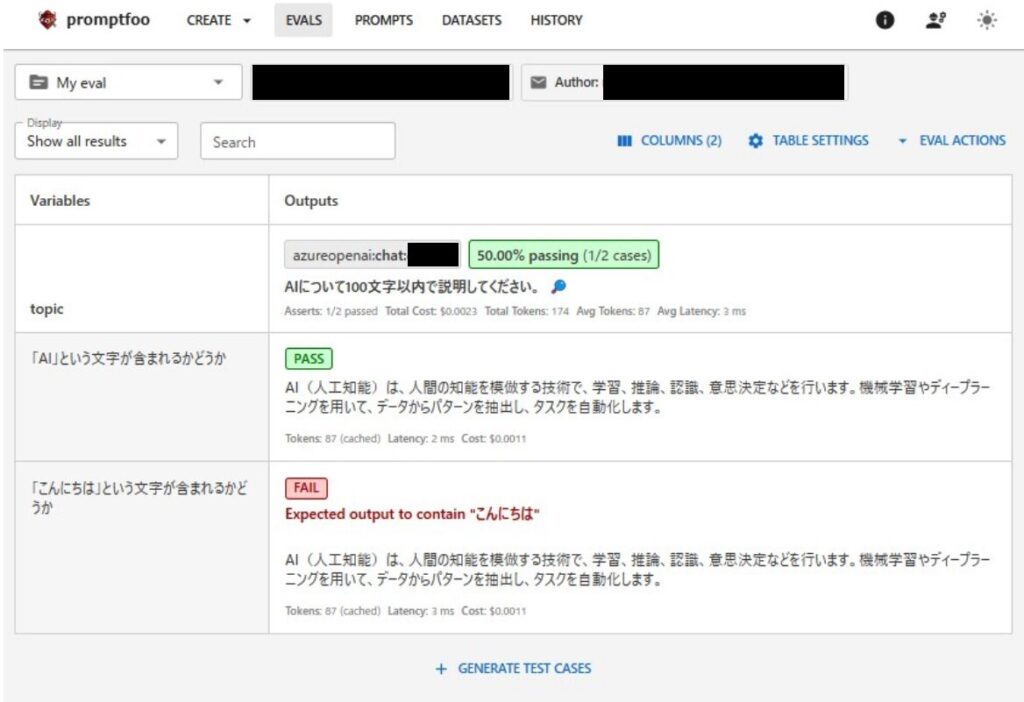
結果を見ると、「AIについて100文字以内で説明してください。」というプロンプトに対してLLMの回答が行われていることが分かります。その回答に対して、”AI”や”こんにちは”といった文字が含まれているかどうかが評価され、結果が出力されます。
今回は、”AI”は含まれているのでPASSとなっており、”こんにちは”は含まれていないのでFAILという結果になりました。(想定通りでした)
promptfooの別な実行例(LLM-as-a-Judgeによる評価)
では、別な実行例も見てみましょう。
先ほどの例では、評価時にLLMは使用していませんでしたが、次はLLMを使用する評価、LLM-as-a-Judgeを行ってみましょう。まずはコード例を以下に記載します。
description: "My eval"
prompts:
- "AIについて100文字以内で説明してください。"
providers:
- id: azureopenai:chat:xxxxxx #deploymentName
config:
apiHost: 'https://xxxxxxxx.openai.azure.com'
defaultTest:
options:
provider:
text:
id: azureopenai:chat:xxxxxx #deploymentName
config:
apiHost: 'https://xxxxxxxx.openai.azure.com'
embedding:
id: azureopenai:embeddings:xxxxxx #deploymentName
config:
apiHost: 'https://xxxxxxxx.openai.azure.com'
tests:
- vars:
topic: プロンプトと回答の相関
assert:
- type: answer-relevance
threshold: 0.7
- vars:
topic: AIの説明があるか
assert:
- type: llm-rubric
value: AIについて説明されていますか?
- vars:
topic: 挨拶が行われているか
assert:
- type: llm-rubric
value: こんにちはという挨拶は行われましたか?
LLMを使った評価を行う場合は、promptfooconfig.yaml に「defaultTest」というパラメータを入れてあげる必要があります。今回は、動作することをまず確認したかったので、回答を生成するLLMと同様のAzure OpenAI Serviceを評価でも使用するように設定しています。評価方法によって、LLMを使うかembeddingモデルを使うか、またはその両方か、が変わるためどちらも設定しておくと良いです。(例では、両方使用しています)
※本来、LLM-as-a-Judgeを行う場合、回答生成用に使用したLLMとは別 かつ 性能が同等以上の別なLLMを設定してあげるのが望ましいです。(評価時にバイアスがかかってしまう可能性があるため)
また、今回テスト方法を指定するパラメータ“assert -> type”を以下の値にしています。
- answer-relevance:
回答が元のプロンプトに関連しているかをチェックする。
関連度の基準は“threshold”パラメータで指定する。 - llm-rubric:
「defaultTest」で指定した言語モデルを使用して回答を評価し、与えられた評価基準を満たしているかをチェックする。評価基準は“value”パラメータで指定する。
こちらのコードを実行した結果が以下となります。
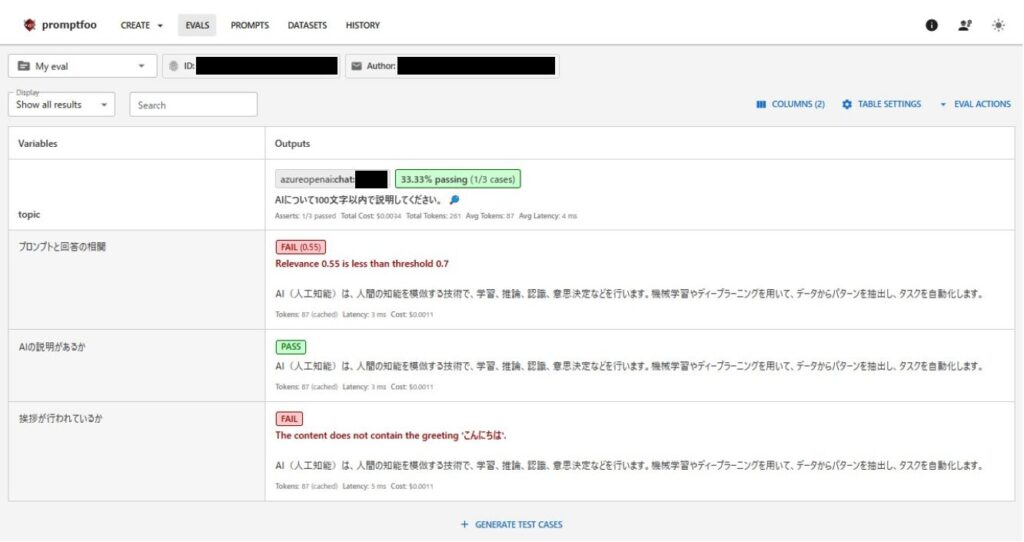
answer-relevanceの評価結果はFAILとなりました。内容的には相関がありそうですが、プロンプトの文が短かったこともありAIという単語以外の部分が相関なしと判断されてしまったのかなと考察しました。
llm-rubricの評価結果は期待通りで、”AIの説明があるか”に対しては、PASS、”挨拶が行われているか”に対してはFAILという結果となりました。
promptfooの実行例(事前に準備した回答を評価する場合)
これまで紹介した実行例は、promptfoo実行時にLLMで回答を生成して評価する方法でした。
次は、事前に別なLLMで得た回答を使って評価を行う方法を紹介します。
まずは、以下のファイルを準備します。
- outputs.json:事前に別なLLMで得た回答を記載します。(例にある”tags”は結果を見やすくするために使用します)
- asserts.yaml:評価方法を記載します。
- promptfooconfig.yaml:評価方法がLLM-as-a-Judgeとなっている場合に、評価で使用するLLMを記載します。
[
{ "output": "Hello world", "tags": ["foo", "bar"] },
{ "output": "Greetings, planet", "tags": ["baz", "abc"] },
{ "output": "Salutations, Earth", "tags": ["def", "ghi"] }
]- type: llm-rubric
value: Helloという文字が含まれますか?description: "My eval"
defaultTest:
options:
provider:
text:
id: azureopenai:chat:xxxxxx #deploymentName
config:
apiHost: 'https://xxxxxxxx.openai.azure.com'
embedding:
id: azureopenai:embeddings:xxxxxx #deploymentName
config:
apiHost: 'https://xxxxxxxx.openai.azure.com'これを以下のコマンドを使って実行しましょう。
※promptfooconfig.yamlは指定していませんが、自動で読み込まれます。
promptfoo eval --assertions asserts.yaml --model-outputs outputs.jsonすると以下のような結果となりました。
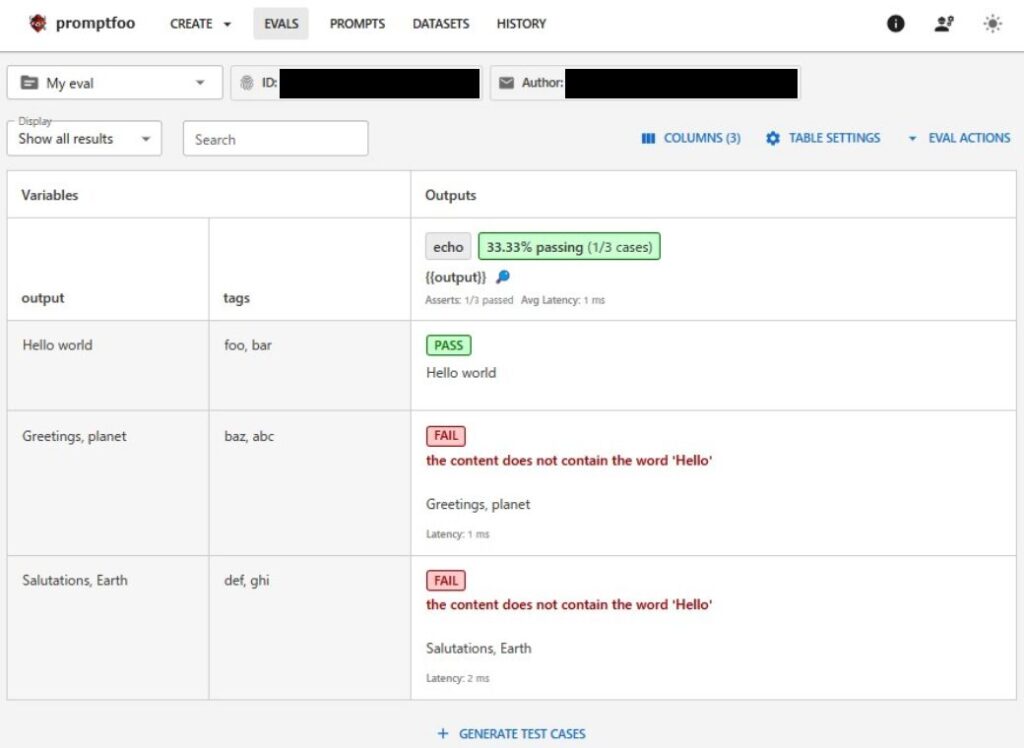
outputs.jsonで与えてあげた回答ごとに、asserts.yamlで指定した評価方法で評価できていることが分かります。結果も想定していた通りで、Hello worldという回答のみ、”Hello”という文字があるのでPASSとなっています。
この方法で評価を行う場合、asserts.yamlに記載する評価タイプを複数記載しても一度に複数の評価方法で評価を行ってはくれませんでした。複数ある評価タイプから(不規則?)に一つ選ばれて結果が出るような動作になっていたので、promptfooの方でまだ対応できていないのかもしれません。
promptfooの実行例(LLMの回答をpythonで設定する方法)
続いての例ですが、promptfooconfig.yamlを実行する際に使用するLLMをpythonに置き換える方法です。
このためには以下のファイルを準備します。
- promptfooconfig.yaml:
“providers”で「provider.py」を指定します。
“pythonExecutable”にPCにインストールされているpython3の実行ファイルのパスを指定します。 - provider.py:
LLMの代わりに指定するpythonコード。
関数を指定しない場合は、call_api(prompt, options, context)が実行されます。
return {“output”: XXX} で指定された値が評価されます。
また、pythonコードを実行するために、環境変数にもpython3の実行ファイルパスを設定する必要があります。
・PROMPTFOO_PYTHON:XXXXXXXXXXXXX\python.exe
description: "My eval"
prompts:
- "AIについて100文字以内で説明してください。"
providers:
- id: file://provider.py
config:
pythonExecutable: XXXXXXXXXXXXXXXXXXX\python.exe #python3の実行ファイルパス
tests:
- vars:
topic: 「AI」という文字が含まれるかどうか
assert:
- type: icontains
value: AIdef call_api(prompt, options, context):
raw = context.get("prompt").get("raw")
return {"output": raw}こちらを実行すると以下のような結果となりました。
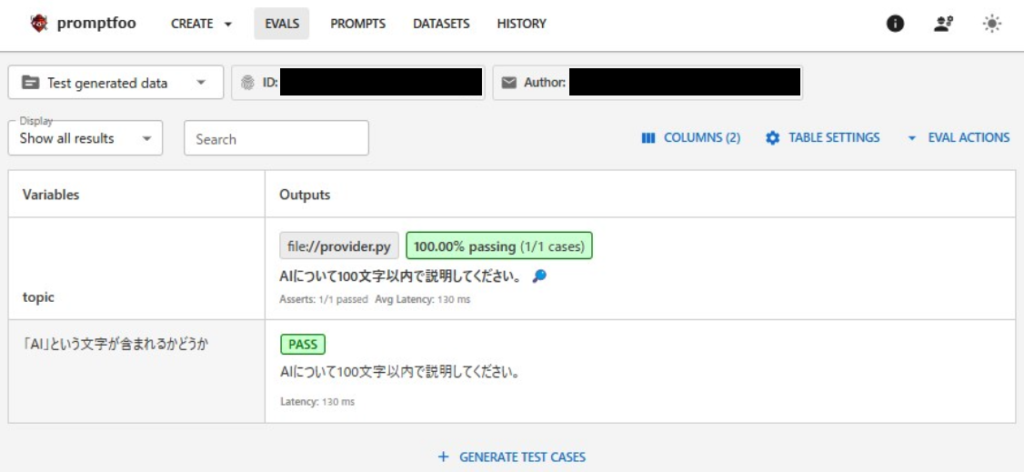
return {“output”: raw}で指定したrawはプロンプトがそのまま入っているので、プロンプト文に対して評価が実行されています。実際に使用する場合は、ユースケースに合わせてpythonで処理した内容を入れるようになります。
まとめ
最後までご覧いただきありがとうございます。
はじめは少し難しいと感じるかもしれませんが、一度動かしてみると「あっ、こんなもんか」と思えたのではないでしょうか?
実際のシステムに組み込むには多少の工夫が必要となるかもしれませんが、かなり使えそうなライブラリと感じております。promptfooは結構機能が多いので、ここで紹介しきれなかった内容もありますが、基本的には公式文書の方に記載があります(動作確認しながらでないと理解が難しいのが難点ですが、、)ので、気になる方はそちらもご参照下さい。
参考までに、設定できる評価方法が記載されている公式ページのリンクを載せておきます。